Luna: A Cluster Autoscaler
Luna is an intelligent autoscaler designed for Kubernetes clusters running in public cloud environments, including Amazon EKS, Google GKE, Oracle OKE, and Microsoft AKS.
Luna continuously evaluates workload demands and cluster state to automatically provision right-size Kubernetes nodes and decommission nodes that are no longer needed. By aligning node capacity with workload requirements, Luna helps ensure reliable pod placement, efficient resource utilization, and reduced operational overhead without manual intervention.
Features
How Luna Works
Luna continuously monitors pods in your Kubernetes cluster and provisions compute capacity as needed to ensure those pods can be placed and run. When new pods appear, Luna evaluates their resource requests and determines how much and what type of capacity is required, creating one or more nodes accordingly.
Luna uses two placement models: bin-packing, which consolidates multiple pods onto shared nodes, and bin-selection, which provisions dedicated nodes for individual pods or specialized workloads. The appropriate model is chosen automatically based on the workload and on user-configurable options, with bin-selection used by default for certain cases such as GPU-enabled workloads.
As workloads complete and capacity is no longer needed, Luna automatically scales the cluster down by reclaiming and removing unused nodes under its management.
When provisioning nodes, Luna selects the most cost-effective available node types that meet the requirements. By default, Luna provisions x86_64 (amd64) nodes. When enabled, Luna can also provision arm64 nodes, provided workloads use compatible container images.
Benefits
Luna helps you:
- Simplify cluster operations by eliminating the need to manually configure and maintain complex autoscaling parameters.
- Reduce operational overhead by automating node provisioning and cleanup based on workload demand.
- Optimize infrastructure costs by matching workloads to the most appropriate compute and reclaiming unused capacity.
- Support multiple cloud providers with a consistent autoscaling model across Amazon EKS, Google GKE, Oracle OKE, and Microsoft AKS, reducing platform-specific complexity.
- Enable teams to focus on delivery by allowing DevOps and platform engineers to spend less time tuning infrastructure and more time supporting business workloads.
Shared and dedicated nodes
Luna allows you to define the criteria used to determine whether pods are placed using bin-selection (bin-select) or bin-packing (bin-pack).
The diagram below illustrates both bin-packing and bin-selection.
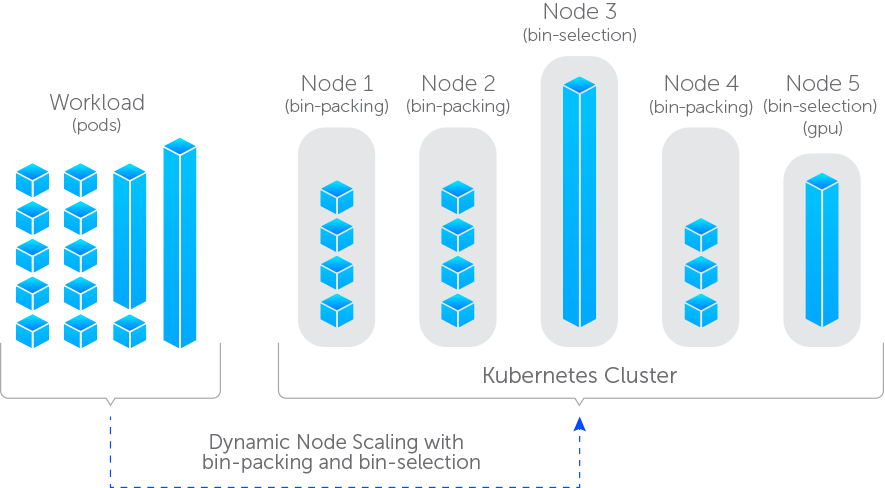
Bin-Selection
Bin-selection places pods on dedicated nodes and is typically used for large, performance-sensitive, or specialized workloads that benefit from isolation. Nodes with GPUs are treated as bin-select by default, though they can be configured to operate as shared nodes if desired.
Bin-packing
Bin-packing places pods on shared nodes and is intended for workloads with modest resource requirements. Administrators can configure the specifications and lifecycle behavior of bin-pack nodes, allowing Luna to balance utilization, cost efficiency, and availability.
Tailored compute
Luna provisions compute capacity based on the characteristics of each workload, rather than relying on a one-size-fits-all node configuration.
Workloads that benefit from isolation or require larger or specialized resources are placed on dedicated nodes using Luna’s bin-selection (or bin-select) model. In this mode, Luna selects an individual node that is purpose-built for a specific pod or a small set of identical pods.
Workloads with lighter resource needs are consolidated onto shared nodes using Luna’s bin-packing (or bin-pack) model. Bin-packing allows multiple pods to share nodes efficiently, improving overall utilization while reducing cost.
By combining bin-selection and bin-packing within the same cluster, Luna ensures that each workload is placed on infrastructure that best matches its needs while maintaining efficient use of cloud resources.
To select the best node, Luna uses the following process:
For both bin-packing and bin-selection, Luna follows a consistent process when selecting node types:
Luna starts with the full set of available instance types for the configured cloud provider. This set is first filtered based on include and exclude rules, such as allowed instance families or architectures.
From the remaining candidates, Luna further narrows the list to instance types that can satisfy the pod’s resource requirements. The eligible instance types are then sorted by price, from lowest to highest.
Finally, Luna selects the most cost-effective instance type that meets all constraints and provisions the corresponding node.
Unmodified workloads
By default, Luna considers pods labeled with elotl-luna=true. Alternatively, you can configure Luna to match custom labels or annotations that align with your existing workload definitions.
No other workload changes are required. Simply apply a label or annotation to your pods, or configure Luna to recognize existing ones, and Luna will dynamically and efficiently provision the appropriate infrastructure.
Specify instance families
Luna allows you to explicitly include or exclude instance families when making scaling decisions. This provides finer control over the types of compute used for your workloads when cost alone is not the primary consideration.
In some cases, the lowest-cost instance that satisfies CPU and memory requirements may not provide adequate performance. For example, a pod with modest CPU and memory needs may generate a high volume of I/O operations, where lower-cost instance families can become a bottleneck. By constraining instance families, Luna can select nodes that better match the performance characteristics required by your workloads.
Specify GPU requirements
Luna supports GPU instances for dedicated nodes. You can specify the type of GPU you would like to run on your nodes:
apiVersion: v1
kind: Pod
metadata:
annotations:
node.elotl.co/instance-gpu-skus: "T4"
...
spec:
containers:
- resources:
limits:
nvidia.com/gpu: 1
Spot pricing
Cloud providers offer discounted compute capacity that can be reclaimed at any time, commonly referred to as spot pricing. This type of capacity is well suited for fault-tolerant or interruption-aware workloads.
Luna supports spot pricing through Spot Instances on Amazon EKS and Azure AKS, Spot VMs on Google GKE, and Preemptible Instances on Oracle OKE. Administrators can enable and control the use of spot capacity to balance cost savings against availability requirements.
Arm64 support
Luna supports both amd64 and arm64 node architectures and can provision nodes using one or both architectures, depending on how it is configured.
By default, Luna provisions amd64 nodes. Luna operates in single-architecture or multi-architecture environments, selecting node architectures based on workload requirements and configured preferences. In mixed-architecture configurations, workloads that do not explicitly specify an architecture are expected to use container images that support multiple architectures.
Persistent Volume Claim support
Luna provides configurable behavior for pods that use Persistent Volume Claims (PVCs), allowing you to control how storage constraints influence scaling and placement decisions.
By default, Luna ignores pods with bound PVCs, unless the placeBoundPVC parameter is set to true. Luna can also be configured to ignore pods that use local storage, depending on the desired behavior.
Pods considered by Luna
By default, Luna provisions compute only for pods that match the configured labels or annotations, as defined by the labels or podAnnotations parameters. Pods that do not match these selectors are ignored by Luna.
The following pods are excluded by default, unless explicitly configured otherwise:
- DaemonSet pods are not considered.
- Pods in the
kube-systemnamespace are not considered, unless that namespace is removed from thenamespacesExcludeparameter. - Pods with an existing node selector (
pod.spec.nodeSelector) are not considered, unless theplaceNodeSelectorparameter is set totrue. - Pods with bound Persistent Volume Claims (PVCs) are not considered, unless the
placeBoundPVCparameter is set totrue.
If a non-DaemonSet pod is not considered by Luna, it will not be placed on nodes provisioned by Luna and must be scheduled on existing cluster capacity.
Node management
Luna manages only a subset of nodes in the cluster. A small number of nodes must exist prior to deploying Luna so that Luna itself can be scheduled and run. At least one node not managed by Luna is required in any cluster where Luna is deployed.
Luna provisions and manages nodes dynamically in response to workload demand and will only scale down nodes that it created. Nodes not managed by Luna are never modified or removed.
Nodes managed by Luna are identified by the following labels:
"node.elotl.co/managed-by": "<luna-release-name>""node.elotl.co/created-by": "<luna-release-name>"
Luna automatically applies these labels to all nodes it provisions, allowing it to track ownership and safely manage node lifecycle operations.