Luna: a Cluster Autoscaler
Luna is an intelligent autoscaler of Kubernetes cluster in clouds (EKS/GKE/OKE) that will provision and cleanup Kubernetes nodes as needed based on the your workloads’ requirements.
Features
Tailored compute
Because each workload is different, Luna uses the pods’ requirement to provision the best nodes for each workload.
Pods with heavy and/or special requirements are assigned to dedicated nodes, while pods with light requirements are placed on ashared nodes to optimize cost, resiliency and availability.
Unmodified workload
By default Luna will consider pods labeled with elotl-luna=true, and you can
set custom tags to match your workload if you desire.
There’s no need to modify your workload otherwise. Just a label to your pods, or configure Luna to match your existing labels, and Luna will be able to run them dynamically and efficiently.
Shared and dedicated nodes
Luna allows to decide what pods run on their own nodes, and which ones run on shared nodes.
Dedicated nodes are useful to ensure optimal performance of large or special pods. Nodes with GPU are all dedicated nodes, and cannot be used as shared nodes at the moment.
Shared nodes are used for pods with modest requirements. Luna allows operators to configure these nodes’ specification and lifecycle.
Specify instance famillies
Luna allows you to include and exclude instance famillies when making scaling decisions. Sometime the cheapest instance that matches a given requirement isn’t good enough. For example a pod with small CPU and memory requirements, may do large amount of IOs and cheaper instance types can be limited in that regard.
Specify GPU requirements
Luna supports GPU instances for dedicated nodes. You can specify the brand, of type of GPU you would like to run on your nodes:
apiVersion: v1
kind: Pod
metadata:
annotations:
node.elotl.co/instance-gpu-skus: "T4"
...
spec:
containers:
- resources:
limits:
nvidia.com/gpu: 1
Spot For EKS and GKE
Luna can run fault-tolerant workloads via Spot on EKS and GKE. Spot nodes can be up to 90% cheaper than regular ones, but Spot nodes may be interuppted at any time. If you have fault-tolerant workloads, running them on Spot will save a signifant on cost.
Arm64 support
Luna can run arm64 workloads. To be able to run arm64 containers, images must be compatible with amd64 and arm64 architectures.
Persistent Volume Claim support
You can configure Luna’s behavior for persistent volume claims depending on what you wish to acheive.
By default Luna ignores pods with bounded Persistent Volume Claims (PVC), unless the placeBoundPVC parameter is true. Luna can also ignore pods with local storage.
AWS Fargate
Luna allows you to use AWS Fargate to further optimize your cloud cost. AWS Fargate nodes have flexible specifications. EC2 virtual machines have pre-determined configurations, while Fargate allows you to use exactly the amount of CPU and memory needed.
If cost optimization is important and your workloads don’t fit well on preset EC2 instances, Fargate may help reduce costs further while running Luna.
Benefits
Luna helps you to:
Simplify cluster operations (no need to create/maintain cluster autoscaling knobs)
Empower DevOps to focus on building their core business (quicker go-to-market)
Prevent wasted spend
Multiple cloud providers
GCP (GKE)
AWS (EKS)
Azure (AKS)1
Oracle (OKE)1
(1) Beta
How Luna works
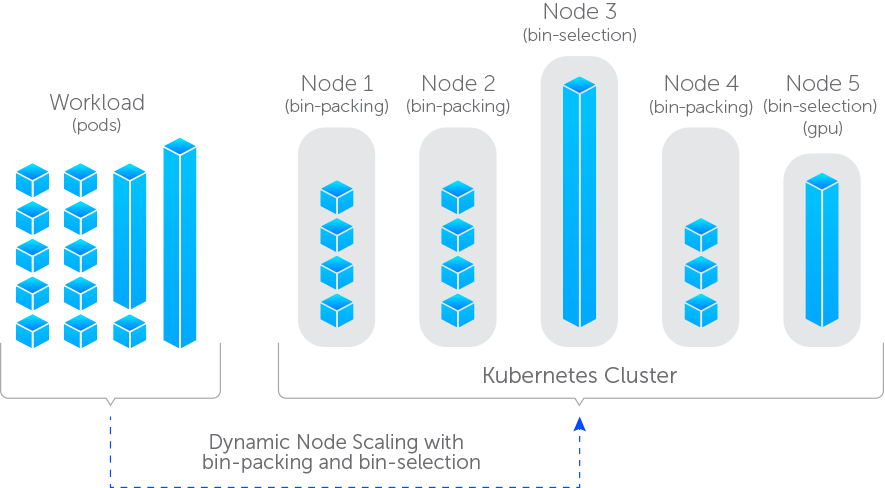
Luna watches pods on your Kubernetes cluster and create nodes based on the new pods’ requirements. Depending on the resource needs, Luna will allocate one or more nodes. In the case of pods with lower resource needs, bin-packing will be chosen where compute is allocated for multiple pods. For larger pods, bin-selection will be chosen, in this case, the right size node will be allocated for each pod. For other use-cases such as workloads with GPU requirements, bin-selection is used. As pods terminate and compute can be reclaimed, Luna will automatically clean up and remove unneeded nodes for which it is managing.
Luna chooses the most economical available node type that satisfies the bin-packing or bin-selection resource requirements. By default, Luna chooses x86_64 nodes. If the option includeArmInstance is enabled, Luna will also consider ARM64 nodes; in this case, the workloads to be placed by Luna must use multi-architecture images that include both x86_64 and ARM64.
Shared nodes with bin-packing
In this mode, Luna tries to bin-pack each pod taken into consideration on bigger nodes. Each pod will get a fixed nodeSelector: node.elotl.co/destination=bin-packing and will be scheduled on one of bigger nodes that luna starts with this label set.
Dedicated nodes bin-selection
In this mode, each pod taken into consideration will get a nodeSelector with value for a new node, right-sized based on the pod's resource request.
For finding the best node, the following method is used:
Luna will take a list of all instance types, then that list will be narrowed down to the ones that can handle resource request. Then, Luna sorts them based on on-demand pricing (cheapest first) and Luna picks the first one (the cheapest).
As compared to bin-packing, node scale down with bin-selection is more aggressive
The below diagram illustrates both bin-packing and bin-selection.
Pods considered by Luna
By default, Luna provisions compute for pods marked with specific labels(set by the labels parameter) with the following exceptions:
- Daemonset pods are not considered.
- Pods in kube-system namespace are not considered.
- Pods with preferred scheduling terms (pod.Spec.Affinity or pod.Spec.NodeSelector) are not considered.
- Pods with bounded Persistent Volume Claims (PVC) are not considered, unless the placeBoundPVC parameter is set to true.
If a non-daemonset pod is not being considered by Luna, it won't be placed in Luna-allocated nodes.
Node Management
Luna does not manage all nodes in your cluster: there is a subset of nodes in the cluster needed before deploying Luna (so it can run somewhere). A minimum of one non-managed Luna node is needed in a cluster that can be used to deploy Luna to. Luna will only scale down nodes that is started and manages.
Luna is only interested in the nodes label with:
"node.elotl.co/managed-by": "<luna-release-name>"
"node.elotl.co/created-by": "<luna-release-name>"
Luna adds these labels to all nodes which it starts.